
Scikit-Learn est une bibliothèque essentielle pour les développeurs et les scientifiques qui souhaitent appliquer des techniques de machine learning (apprentissage machine) en Python. Dans cet article, nous verrons ensemble la librairie Scikit-Learn et passerons en revue ses fonctionnalités clés pour vous aider à maîtriser cette bibliothèque.

Structure et fonctionnalités de Scikit-Learn
Scikit-Learn propose 3 grandes thématiques. La première concerne le pré-traitement des données. En effet, les données que vous allez recevoir seront à coup sûr inutilisable dans l’état où elles seront. Vous devrez donc travailler dessus et Scikit-Learn propose des outils permettant de traiter vos données.
La seconde thématique concerne la sélection de modèle et les types de modèle. Des outils puissants permettent de vous aider à sélectionner le meilleur modèle pour vos données mais également d’optimiser les paramètres du modèle retenu.
Enfin, Scikit-Learn vous propose plusieurs types de modèle selon l’étude que vous souhaitez mener (régression, classification, regroupement). Chaque type de modèle ayant sa particularité, ils seront plus ou moins efficaces suivant l’objectif de votre étude mais également suivant vos données.
Pour chaque modèle que vous entrainerez, vous aurez alors à disposition une panoplie d’indicateurs permettant de juger de la pertinence de celui-ci.
Pré-traitement des données avec Scikit-Learn
La librairie Scikit-Learn met à disposition de nombreux outils et fonctions permettant de transformer les données brutes en quelque chose qui pourra être bien mieux interprétés par les modèle d’apprentissage.
En effet, des données pré-traitées, normalisées, triées sans valeurs aberrantes mais de mieux tirer partie des modèles. Voici un article de la documentation de la librairie Scitkit-Learn illustre les différents phénomènes par la visualisation des données. L’image suivante est issue de l’article.
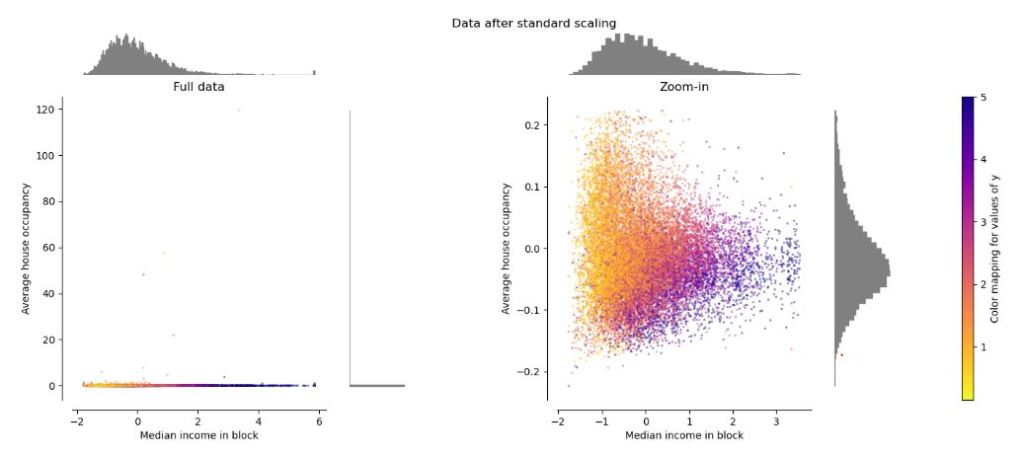
Extraction et normalisation des données
Pour l’extraction de caractéristiques, vous pouvez utiliser des techniques telles que la sélection de variables ou l’extraction de motifs. Scikit-Learn fournit différents modules comme Feature_extraction qui pourra vous aider à transformer un dictionnaire en tableau selon les clés présentes dans celui-ci. Aussi il vous sera possible de convertir un texte en un tableau qui vous permettra d’étudier les mots à l’intérieur de celui-ci.
Quant à la normalisation, elle permet de mettre vos données sur une même échelle, évitant ainsi les problèmes de biais. Vous pouvez utiliser la classe StandardScaler pour centrer sur la moyenne des valeurs ou tout simplement la classe MinMaxScaler pour mettre à l’échelle suivant l’étendue des valeurs.
Voici un exemple simplifié de code utilisant Scikit-Learn issu de la documentation pour extraire des caractéristiques et normaliser les données :
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.feature_extraction import DictVectorizer
# Exemple avec l'extraction de caractéristiques à partir de texte
measurements = [
{'city': 'Dubai', 'temperature': 33.},
{'city': 'London', 'temperature': 12.},
{'city': 'San Francisco', 'temperature': 18.},
]
# Extraction du dictionnaire avec DictVectorizer
vec = DictVectorizer()
donnees_vectorisees = vec.fit_transform(measurements).toarray()
# Affichage des données vectorisées
print(vec.get_feature_names_out())
print(donnees_vectorisees)
# Normalisation des données avec le StandardScaler
scaler = StandardScaler()
donnees_normalisees = scaler.fit_transform(donnees_vectorisees)
# Affichage des données normalisées
print(donnees_normalisees)
# Normalisation des données avec le MinMaxScaler
scaler = MinMaxScaler()
donnees_MinMax = scaler.fit_transform(donnees_vectorisees)
# Affichage des données normalisées
print(donnees_MinMax)
Et voici le résultat de l’exemple précédent :
# Affichage des données vectorisées
['city=Dubai' 'city=London' 'city=San Francisco' 'temperature']
[[ 1. 0. 0. 33.]
[ 0. 1. 0. 12.]
[ 0. 0. 1. 18.]]
# Affichage des données normalisées avec StandardScaler
[[ 1.41421356 -0.70710678 -0.70710678 1.35873244]
[-0.70710678 1.41421356 -0.70710678 -1.01904933]
[-0.70710678 -0.70710678 1.41421356 -0.33968311]]
# Affichage des données normalisées avec MinMaxScaler
[[1. 0. 0. 1. ]
[0. 1. 0. 0. ]
[0. 0. 1. 0.28571429]]Cet exemple vous montre comment utiliser Scikit-Learn pour extraire des caractéristiques et normaliser les données. Le StandardScaler permet de ramener les données autour d’une valeur moyenne et une variance unitaire tandis que le MinMaxScaler ramène les valeurs entre 0 et 1. N’hésitez pas à consulter la documentation de Scikit-Learn pour plus d’informations sur ces techniques et d’autres fonctionnalités disponibles.
Réduction de la dimension du problème
La réduction de la dimension du problème est une technique essentielle dans le domaine de l’apprentissage automatique. Scikit-learn propose plusieurs algorithmes permettant de réaliser cette opération dont notamment le PCA (Principal component analysis). D’autres algorithmes sont disponibles mais cela sortirait du scope de cet article de les présenter.
Pour illustrer ce que fait l’algorithme PCA, imaginons que vous essayez de déterminer la famille d’un animal par le biais de trois facteurs : la longueur du corps, le nombre de pattes et la longueur de la queue. Nous allons ensuite considérer que ce dernier paramètre n’est pas influent pour déterminer la famille de l’animal. En appliquant l’algorime PCA aux trois facteurs, le résultat donnera alors un nombre réduit de facteur où la longueur de la queue sera supprimé. Le problème aura donc été réduit en passant de 3 dimensions à seulement 2 en limitant la perte d’information.
Ces algorithmes de réduction de la dimension proposés par Scikit-Learn peuvent être utilisés selon les besoins spécifiques de votre projet. Je vous conseille fortement d’explorer ces différentes techniques afin de choisir celle qui convient le mieux à vos données et objectifs d’apprentissage automatique.
Algorithmes de classification avec Scikit-Learn
Scikit-Learn offre une large gamme d’algorithmes de classification. Les algorithmes de classification permettent de prédire à quelle catégorie appartient un set de données. Par exemple, compte tenu des différentes propriétés d’une transaction (montant, heure de la journée, …), il est possible de développer un modèle de prédiction pour détecter les transactions frauduleuses. Dans cette section nous vous donnerons les modèles disponibles sans rentrer dans le détail de chacun car cela prendrait trop de temps.
Les types de modèle les plus populaires sont les classificateurs linéaires et des arbres de décision. Voici les algorithmes les plus connus :
- Classificateur linéaire : ils utilisent une combinaison linéaires des paramètres pour classifier les données. Les modèles les plus utilisés sont « Logistic Regression« , « Linear SVM » et « Naive Bayes« .
- Les arbres de décisions : ils sont très populaires. Telles les ramifications des branches (ou des racines), un arbre de décision va décomposer la logique de choix en fonction des paramètres et des probabilités associées.
- SVM (Support Vector Machine) : les classificateurs SVM essaient de séparer les populations via des formes géométriques (vecteurs, plans, …).
- Forêts aléatoires : (Random Forests) comme son nom l’indique, pour avoir une forêt, il faut plusieurs arbres. Ce modèle va combiner plusieurs modèles d’arbre de décision afin de les faire travailler ensemble. L’ensemble de modèles ainsi formé permet d’être plus général. Chaque arbre fera sa prédiction et la réponse finale sera une combinaison de toutes les réponses.
- K-Nearest Neighbors (KNN) : Ce modèle vient tout simplement analyser les plus proches voisins d’un point pour lui attribuer une classification. Ce type de modèle est simple et efficace mais leur performance dépend énormément du type de données que vous avez. Je vous invite à visualiser vos données afin de vous aider à sélectionner le meilleur modèle de prédiction.
- Naive Bayes : ce modèle se base sur des méthodes probabilistes et fait également l’hypothèse que tous les facteurs sont indépendants entre eux. Si cette hypothèse est respectée, ce modèle fonctionne très bien avec des sets de données à grande dimension.
Ce ne sont que quelques exemples parmi tous les modèles qui existent. La documentation en ligne vous donnera tous les renseignements dont vous aurez besoin. Rappelez-vous que le meilleur moyen de savoir si un modèle fonctionne est de le tester.
Voici un exemple de classification via un arbre de décision. Les données proviennent de la librairie Scikit-Learn. En effet, la librairie met à disposition des sets de données pouvant être utilisés pour différents exemples. Cela vous évitera d’avoir à formatter vos données mais vous pourrez également comparer vos résultats. Cet exemple est directement issu de la documentation.
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree
# Chargement des données
iris = load_iris()
X = iris.data
y = iris.target
# Entrainemenet
clf = DecisionTreeClassifier().fit(X, y)
plt.figure()
clf = DecisionTreeClassifier().fit(iris.data, iris.target)
# Affichage de l'arbre de décision
plot_tree(clf, filled=True)
plt.title("Arbre de décision avec tous les facteurs")
plt.show()
Afficher l’arbre permet de visualiser les décisions successives qui ont été déterminées pendant l’apprentissage. Un arbre de décision est en fait une succession de conditions. Suivant la valeur du facteur et du seuil déterminé, l’arbre de décision ira d’un coup ou l’autre du nœud considéré.
Algorithmes de régression dans Scikit-Learn
La régression est utilisée afin de construire un modèle mathématique permettant de prédire la réponse d’un système sur le domaine d’étude. Elle est généralement utilisées avec des valeurs dites continues, c’est-à-dire variables dans le domaine d’étude. Scikit-Learn propose plusieurs algorithmes de régression, tels que la régression linéaire, la régression logistique et la régression polynomiale.
Voici quelques-uns des algorithmes de régression les plus couramment utilisés dans Scikit-Learn :
- Régression linéaire (ou moindres carrés) : la régression classique sur un nuage de points. L’algorithme va chercher à minimiser l’erreur d’ajustement de la courbe par rapport au nuage de points.
- Régression polynomiale : elle étend la régression linéaire en utilisant des fonctions polynomiales pour modéliser la relation entre les facteurs et la réponse du système. Il est donc possible d’avoir des comportements non-linéaires et également de modéliser les interactions.
- Régression logistique : cette régression est utilisée pour classifier en fonction des variables d’entrée. La sortie n’est pas une variable continue dans ce cas.
Voici un exemple de régression polynomiale :
# Import des librairies
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.metrics import max_error, mean_absolute_error
from sklearn.pipeline import Pipeline
# Fonction graphique
def plot_contour(x, y, z):
plt.style.use('_mpl-gallery-nogrid')
# plot
fig, ax = plt.subplots()
ax.set_xlabel(x.name)
ax.set_ylabel(y.name)
ax.tricontourf(x, y, z)
plt.show()
# Création des données
df = pd.DataFrame({"Farine (g)": [600, 600, 800, 800],
"Beurre (g)": [100, 200, 100, 200],
"Qualité de la crêpe": [45, 15, 95,60]
})
columns = df.columns
# Définition du modèle et de la pipeline
# PolynomialFeatures permet d'intégrer les intéractions
degree = 1
interaction = False
model = Pipeline([
('poly', PolynomialFeatures(degree=degree,interaction_only=interaction)),
('linear', LinearRegression(fit_intercept=False))
])
# Apprentissage
facteurs = columns[:2] # Sélection des colonnes pour les facteurs
reponse = columns[2] # Sélection de la colonne pour la réponse
x_train = df[facteurs]
y_train = df[reponse]
model.fit(x_train, y_train)
# Prédiction avec le modèle
y_pred = model.predict(x_train)
# Calcul de la performance du modèle
model_score = model.score(x_train, y_train)
max_err = max_error(y_train, y_pred)
mae = mean_absolute_error(y_train, y_pred)
print(f'The model score (R2) is : {model_score:.3f}')
print(f'The max error score is : {max_err:.2f}')
print(f'The mean absolute error score is : {mae:.2f}')
# Visualisation des données
plot_contour(x_train["Farine (g)"], x_train["Beurre (g)"], y_pred)Voici les données affichées par le script :
Farine (g) Beurre (g) Qualité de la crêpe
0 600 100 45
1 600 200 15
2 800 100 95
3 800 200 60
The model score (R2) is : 0.998
The max error score is : 1.25
The mean absolute error score is : 1.25
L’exemple précédent met en place une régression linéaire sur deux facteurs. Une fois le modèle entrainé, on affiche sa performance. Le modèle dans ce cas est très bon avec une erreur faible sur la qualité de la crêpe. La conclusion est donc la suivante : pour avoir des crêpes de bonne qualité, il faut diminuer le beurre et augmenter la quantité de farine. Je me permets de préciser est juste un exemple et en aucun le résultat d’une étude 🙂
Clustering (regroupement) avec Scikit-Learn
Le clustering permet de regrouper des données similaires sans étiquettes prédéfinies. Scikit-Learn propose des algorithmes de clustering populaires tels que le K-means, le DBSCAN et le Gaussian Mixture. Ces algorithmes sont souvent utilisés dans le cas de modèle non-supervisé. Le terme « non-supervisé » signifie que nous ne travaillons pas sur la réponse du système mais sur le système lui-même. L’idée est d’étudier les composantes du système pour en sortir des tendances, des groupes, des facteurs influents. Ainsi, ces outils permettent de mieux comprendre le jeu de données à disposition. Voici une image tirée de la documentation (voici le lien) qui illustre les résultats de différents algorithmes de « clustering » suivant le jeu de données que vous avez à traiter.
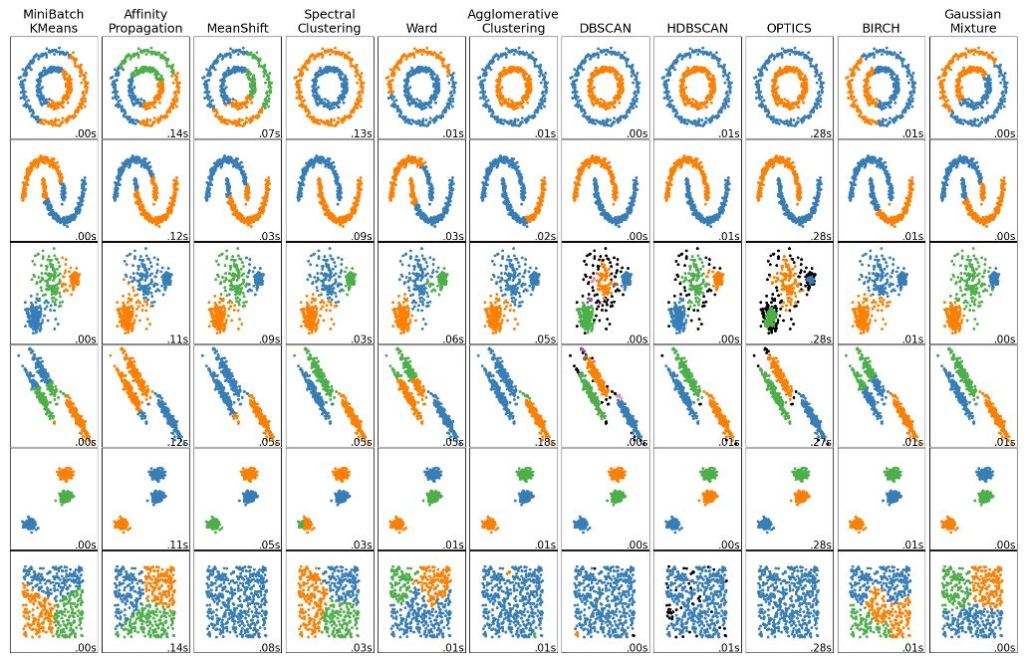
L’algorithme KMeans calcule la distance avec les points voisins pour identifier à quel groupe chaque point appartient. Cet algorithme est simple et efficace. Cependant, pour des géométries de population complexe, ses performances sont limitées.
Le DBSCAN quant à lui permet de capturer des géométries plus complexes.
Évaluation des modèles avec Scikit-Learn
L’évaluation des modèles est cruciale pour mesurer leur performance et prendre des décisions éclairées. Scikit-Learn fournit des méthodes avec les modèles d’apprentissage permettant de calculer leur performance. Cette section présente les métriques usuelles dans le domaine du Machine Learning.
Chaque modèle disponible dans la librairie Sckikit-Learn possède une méthode « .score » permettant de renvoyer un indicateur de performance. La façon dont est calculé ce score est spécifique à chaque modèle. Vous devrez donc aller dans la documentation pour plus de détails pour chaque modèle.
De plus, le module « metrics » est disponible afin de rajouter des indicateurs à votre convenance. En effet, un seul indicateur est rarement suffisant pour juger la performance d’un modèle. Vous aurez donc besoin de rajouter des critères afin de valider votre modèle. Nous allons voir ensemble comment évaluer la performance d’un modèle de régression et de classification avec les indicateurs populaires.
Régression
La variance expliquée ou le coefficient R²
Le calcul de la variance expliquée et du coefficient R² sont très proche. Il est tout de même conseillé d’utiliser le « r2_score » car la variance expliquée ne prend pas un éventuel décalage constant dans les données. Le coefficient R² quant à lui additionne l’écart au carré de toutes les données. Dans la définition de la variance, si elle s’applique à un échantillon de la population, le dénominateur vaut (n-1) et non pas n. De ce fait, une légère différence peut être observée. Néanmoins, dans le cas d’un décalage constant, la différence sur les résultats est flagrante.
from statistics import variance
import numpy as np
import matplotlib.pyplot as plt
y_true = np.array([1, 2, 3, 4])
y_pred = np.array([7, 8, 9, 10])
var_true = variance(y_true)
var_pred = variance(y_true - y_pred)
somme_carre_true = ((y_true-y_true.mean())**2).sum()
somme_carre_pred = ((y_true-y_pred)**2).sum()
print(f'Coefficient R² = {1-somme_carre_pred/somme_carre_true:.3f}')
print(f'Variance expliquée = {1-var_pred/var_true:.3f}')
x = np.linspace(1,4,4)
plt.plot(x,y_true,c = 'green',label='y_true')
plt.plot(x,y_pred,c = 'darkorange',label='y_pred')
plt.xlabel('X')
plt.ylabel('Y')
plt.title('Visualisation des données réelles vs prédiction')
plt.legend()Coefficient R² = -27.800
Variance expliquée = 1.000
La variance expliquée est de 100% alors que le coefficient R² vaut -27.8. Le « r2_score » nous alerte donc sur un problème dans notre modèle. Le 100% de la variance expliquée montre qu’en réalité notre modèle permet d’estimer parfaitement la variation des données réelles. Cependant, pour valider notre modèle, nous avons besoin d’un autre indicateur. Nous allons voir ensuite trois indicateurs utiles concernant l’erreur faite par le modèle par rapport aux données réelles.
L’erreur maximale, l’erreur moyenne absolue, erreur moyenne au carré
Ces trois calculs d’erreur permettent de déterminer comme leur nom l’indique l’erreur maximale sur les données, l’erreur moyenne absolue (MAE) et l’erreur moyenne au carré (MSE).
La MAE permet entre autre d’évaluer l’erreur systématique que fera le modèle sur la prédiction. Ainsi, vous pourrez comparer la valeur de cette erreur à l’ordre de grandeur de la réponse.
En reprenant l’exemple précédent, calculons ces erreurs.
from sklearn.metrics import max_error, mean_absolute_error, mean_squared_error
y_true = np.array([1, 2, 3, 4])
y_pred = np.array([7, 8, 9, 10])
print(f'Maximum error = {max_error(y_true, y_pred):.2f}')
print(f'Mean absolute error = {mean_absolute_error(y_true, y_pred):.2f}')
print(f'Mean squared error = {mean_squared_error(y_true, y_pred):.2f}')Maximum error = 6.00
Mean absolute error = 6.00
Mean squared error = 36.00Cette fois-ci, avec ces indicateurs, on observe une erreur conséquente sur la prédiction. L’erreur est bien constante car le maximum de celle-ci est égal à la moyenne absolue.
Classification
Dans le cas de la classification, le modèle va devoir prédire la catégorie à laquelle appartient le jeu de données. Par exemple, dans un cas simple pour déterminer si une image est un chat ou non, quatre cas de figures peuvent apparaitre :
- Vrai positif : le modèle donne la bonne prédiction, l’image est bien un chat
- faux positif : le modèle prédit que c’est un chat alors que ce n’est pas le cas
- faux négatif : le modèle prédit que c’est pas un chat alors qu’en réalité, c’est bien un chat
- Vrai négatif : le modèle donne la bonne prédiction, ce n’est pas un chat
Le faux positif est une erreur d’ordre 1 alors que le faux négatif est une erreur d’ordre 2. Par exemple, si le modèle est utilisé pour contrôler une pièce, si celui-ci donne un faux positif (la pièce est bonne), celle-ci sera commercialisée et un client aura une pièce défectueuse. Dans le cas contraire, si la pièce est bonne, le modèle aura décidé que c’est un rebut. La valeur ajoutée sera jetée, c’est de la perte sèche mais il n’y a pas risque qu’une pièce défectueuse arrive chez le client. Le second cas est donc préférable. Une image humoristique que j’apprécié illustre ces cas de figures :

Pour déterminer la précision du modèle, on peut alors construire un tableau à double entrée avec la donnée réelle et les prédictions. Le tableau ainsi créé s’appelle la matrice de confusion. Reprenons notre exemple du chat :
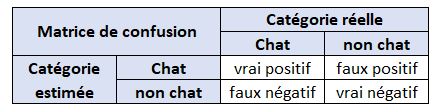
Maintenant que nous avons vu la matrice de confusion, nous pouvons introduire plusieurs indicateurs permettant de jauger la performance du modèle. Tout d’abord, voici le résultat d’un modèle de classification pour identifier un chat :

Ainsi nous pouvons calculer les indicateurs suivants : le taux de vrai positif (Sensitivity ou Recall), le taux de vrai négatif (specificity), la précision (Positive Predictive value), la performance globale (accuracy). Voici une illustration qui montre leur calcul :

Ensuite, à partir de ces indicateurs primaires, d’autres indicateurs combinés existent afin d’estimer la performance globale du modèle. C’est le cas du « F1 score ».

Cette équation traduit un pourcentage de vrai positif par rapport au total des vrais positifs et des mauvaises prédictions. Par exemple, pour un F1-score de 50%, on obtient alors la relation suivante :

Cette équation peut être interprétées de la manière suivante : Pour une prédiction correcte, deux seront fausses. Autant dire qu’un F1-Score de 50% n’est vraiment pas terrible. Voici un graphique montrant l’évolution de l’indicateur en fonction du taux de vrais positifs. La ligne verte donne la correspondance du taux de vrais positifs pour un score de 50%.

D’autres indicateurs existent comme la courbe de ROC ou l’aire sous la courbe de ROC. Ceux-ci pourront faire l’objet d’un autre article.
Tous ces indicateurs sont disponibles dans la librairie Scikit-Learn. Ainsi, vous pourrez définir vous-même les indicateurs les plus pertinents pour vos modèles. Leur évaluation est une étape cruciale pour garantir une performance optimale.
Conclusion
Nous avons vu au travers de cet article les principales fonctionnalités qu’offre la librairie Scikit-Learn. Cette bibliothèque est vraiment facile d’utilisation afin de développer votre propre modèle de régression ou classification. Vous pourrez ainsi construire vos premiers projets de machine learning.
Scikit-Learn est en constant développement et la documentation en ligne vous permet d’approfondir vos recherches si besoin. Une grande panoplie d’exemples est disponible ce qui est très utile pour vous inspirer et gagner du temps. Pour générer des graphiques, la librairie s’appuie sur Matplotlib. Si vous souhaitez découvrir cette librairie, j’en parle dans cet article.
Pour démarrer votre projet d’apprentissage machine, vous devrez utiliser les différents modules vus dans cet article. Dans un premier temps, vous devrez réaliser un pré-traitement sur les données. En effet, la plupart ne sont pas forcément significative. Vous devrez peut-être les réarranger pour que celles-ci soient utilisable par le modèle. Ce premier travaille est vraiment crucial pour la réussite de votre projet.
Une fois que vos données sont prêtes, il est maintenant temps de rechercher le modèle le plus pertinent. Pour se faire, vous pourrez alors en tester plusieurs. Pour chaque modèle, vous avez également différents paramètres à ajuster au besoin. Des modules de la librairie Scikit-Learn peuvent vous aider, par exemple « gridsearchCV » qui va tester différentes configurations de paramètres et ressortir le modèle qui donne les meilleurs performances.
Pour évaluer les performances d’un modèle, différentes métriques sont disponibles. Suivant le type de modèle, vous n’utiliserez pas les mêmes comme nous l’avons vu dans la section dédiée. Suivant l’objectif que vous aurez, vous devrez choisir des métriques appropriées.
Il ne reste maintenant plus qu’à vous lancer. Commencez par un petit modèle et complexifiez vos projets au fur et à mesure. C’est la meilleur approche pour bien sentir les possibilités de chaque modèle et surtout pour bien maîtriser la préparation des données.
Merci de m’avoir, bon apprentissage … machine 🙂
N’hésitez pas à laisser un commentaire,
Benjamin
Article hyper détaillé et on sent la maîtrise et la passion au travers de toutes ces lignes! 😉
Merci beaucoup pour ton commentaire !